 By
By 
The previous five years of AI were defined by a single assumption: that serious intelligence required serious infrastructure. Massive data centres, stable fibre connections, monthly API bills. The conversation has shifted. On April 2, 2026, Google released the Gemma 4 family of models and the most interesting place to run them is not a server rack. It is your phone.
I spent a day running the Gemma 4-2B and Gemma 4-4B on a OnePlus Nord CE 5 with 8GB RAM and a Mali G615-MC6 GPU. No cloud. No API key. No internet connection required. What I found changed how I think about what a phone is capable of and exposed a capability gap between the two models that every developer and student in Kenya needs to understand.
Getting Started: Google AI Edge Gallery
You do not need a rooted device, a terminal, or any technical setup to run Gemma 4 on Android. The entry point is the Google AI Edge Gallery, currently available as a Developer Preview on the Google Play Store. It is an 11MB download ( smaller than most news apps ) that serves as a container for on-device AI workloads.
Open the gallery and you are presented with a library of seven models optimised for different tasks. For this test I focused on the Gemma 4 E2B (2.3B effective parameters) and E4B (4.5B effective parameters) instruction-tuned variants.
The first reality check comes at model initialisation. Selecting a model triggers a roughly one-minute loading process as weights are transferred into RAM. On an 8GB device, Android will greet you with a warning:
"Your system RAM may not be enough; the app might crash."
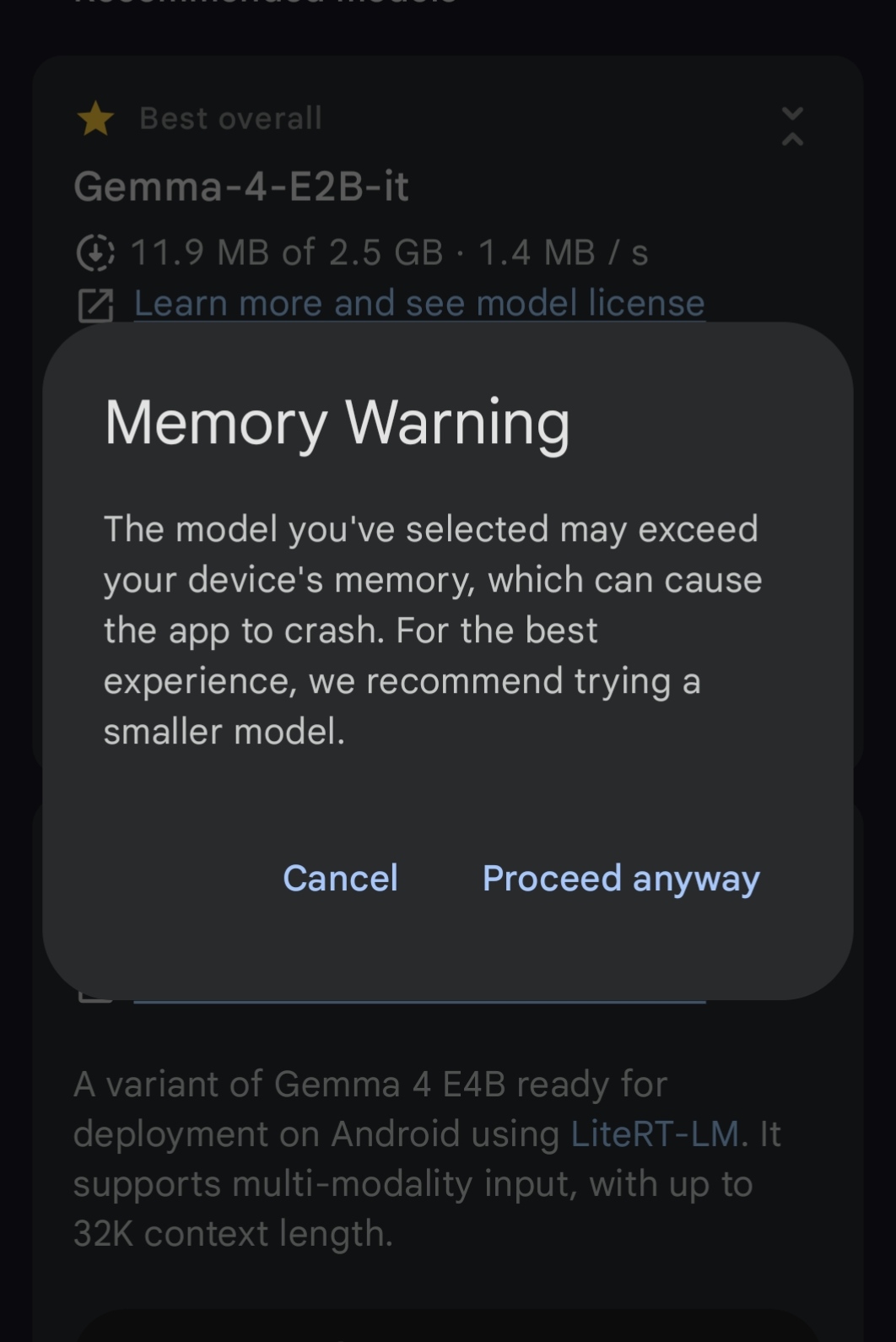
Tap "Proceed Anyway." As we will see, the Dimensity chipset and Mali GPU are more resilient than the warning suggests, though that resilience has limits we will get to.
Context: What I Am Comparing Against
For reference, I have been running Llama 3.1 8B on my HP EliteBook 840 G6 ( a laptop with 12GB RAM and no dedicated GPU, everything on CPU ) via Ollama with AnythingLLM as the interface. It achieves around 20 tokens per second. Slow, but functional for a CPU-only setup.
The OnePlus is a fundamentally different architecture. The Mali GPU's LiteRT-LM (formerly TensorFlow Lite) optimisation stack changes the throughput dynamic entirely. What follows is what that difference looks like in practice.
Test 1: Content Generation Speed
Prompt: Write a 300-word editorial for a tech news site regarding the shift toward local-first AI in Kenya for 2026. Focus on the benefits for privacy and latency.
Gemma 4-2B: 24.9 seconds
The output was coherent, well-structured, and immediately usable. The 2B model produced a polished editorial with specific Kenyan context — referencing data sovereignty, rural clinics, Swahili language models, and latency in areas with inconsistent connectivity. From the moment I pressed send, text began flowing almost immediately. For a developer building a content generation tool, a Swahili chatbot, or a rapid drafting interface, 24.9 seconds for 300 words on a mid-range phone is a genuinely impressive result.
Gemma 4-4B: 47.3 seconds
Nearly double the time. The output was also well-structured and contextually appropriate, with slightly more sophisticated framing of the data sovereignty argument. But for content generation, the quality difference between 2B and 4B does not justify the speed trade-off. On this task, 2B wins clearly.
The 2B model at this task feels like an extension of your own thinking. Fast enough that the wait does not break your flow.
Test 2: The Reasoning Test — Where Everything Changed
This is the test that defines the article. I gave both models a standard university-level analytical chemistry problem, the kind that appears in second-year coursework at the University of Nairobi's Chiromo campus.
Prompt: A student titrates 25.0 mL of 0.10 M CH₃COOH with 0.10 M NaOH. Calculate the pH at the equivalence point. (Ka of acetic acid = 1.8 × 10⁻⁵)
This problem requires a specific chain of logic. At the equivalence point of a weak acid-strong base titration, the acid is fully consumed and the solution contains only the conjugate base, sodium acetate. The acetate ion undergoes hydrolysis, producing a basic solution. The correct method requires calculating the hydrolysis constant (Kh = Kw/Ka), then solving for [OH⁻], then converting to pH. The answer must be above 7 because the solution is basic.
Gemma 4-2B: 59.8 seconds — Wrong
The 2B model produced a beautifully formatted, step-by-step solution. Clean LaTeX equations, logical-looking progression, confident conclusion.
The answer was 4.74. Which is the pH at the half-equivalence point, the point where half the acid has been neutralised and pH = pKa. The model pattern-matched to a Henderson-Hasselbalch calculation it had seen many times, applied it to the wrong scenario, and delivered the wrong answer with complete confidence.
In a chemistry lab this is a failing grade. For a student relying on an offline AI tutor to check their work in the field, it is worse than no answer, it is a confidently wrong answer.
Gemma 4-4B: 3.5 minutes — Correct
The phone became noticeably warm. The Mali GPU ran at full capacity for three and a half minutes. The app did not crash.
The 4B model correctly identified that the equivalence point produces a solution of sodium acetate, a salt of a weak acid and strong base. It set up the hydrolysis equation for the acetate ion, calculated Kh = Kw/Ka = 5.56 × 10⁻¹⁰, solved for [OH⁻] = 5.27 × 10⁻⁶ M, calculated pOH = 5.28, and arrived at pH = 8.72.
Correct. Basic. Exactly what the chemistry demands.
This is the result that reframes everything. A 4.5 billion parameter model, running entirely on a mobile GPU, with no internet connection, solved a university-level reasoning problem that an 8B laptop model would likely handle without difficulty and did so correctly when the smaller mobile model failed. The architecture matters as much as the parameter count. Gemma 4's design allows the 4B to outperform what raw numbers would suggest.
Test 3: Structured Data Generation
Prompt: Generate a valid JSON object for a car listing on a marketplace. Include keys for make, model, year, price_kes, and a features array. Make it for a 2024 hybrid SUV.
Gemma 4-2B: 9 seconds Gemma 4-4B: 14 seconds
Both models produced valid, well-structured JSON. The 4B's price estimate (Ksh 4,500,000) was more realistic for Kenya's market than the 2B's Ksh 25,000,000. Both outputs were immediately usable in a production pipeline. For developers building marketplace apps, inventory tools, or any application that needs structured data generated locally without an API call, both models work reliably for this task.
Beyond Text: What Else the App Can Do
The Google AI Edge Gallery is more than a chat interface. A few other features worth knowing about:
Ask Image — upload a photo and ask anything about it. Gemma 4 is natively multimodal. Restricted to 10 images per chat session.
Audio Scribe — transcribes or translates audio directly on device. No audio data leaves the phone.
Built-in Skills — the app ships with seven pre-built skill modules: Calculate Hash, Kitchen Adventure, Mood Tracker, QR Code generator, Query Wikipedia, Send Email, and Text Spinner. Each extends what the model can do beyond pure text generation.
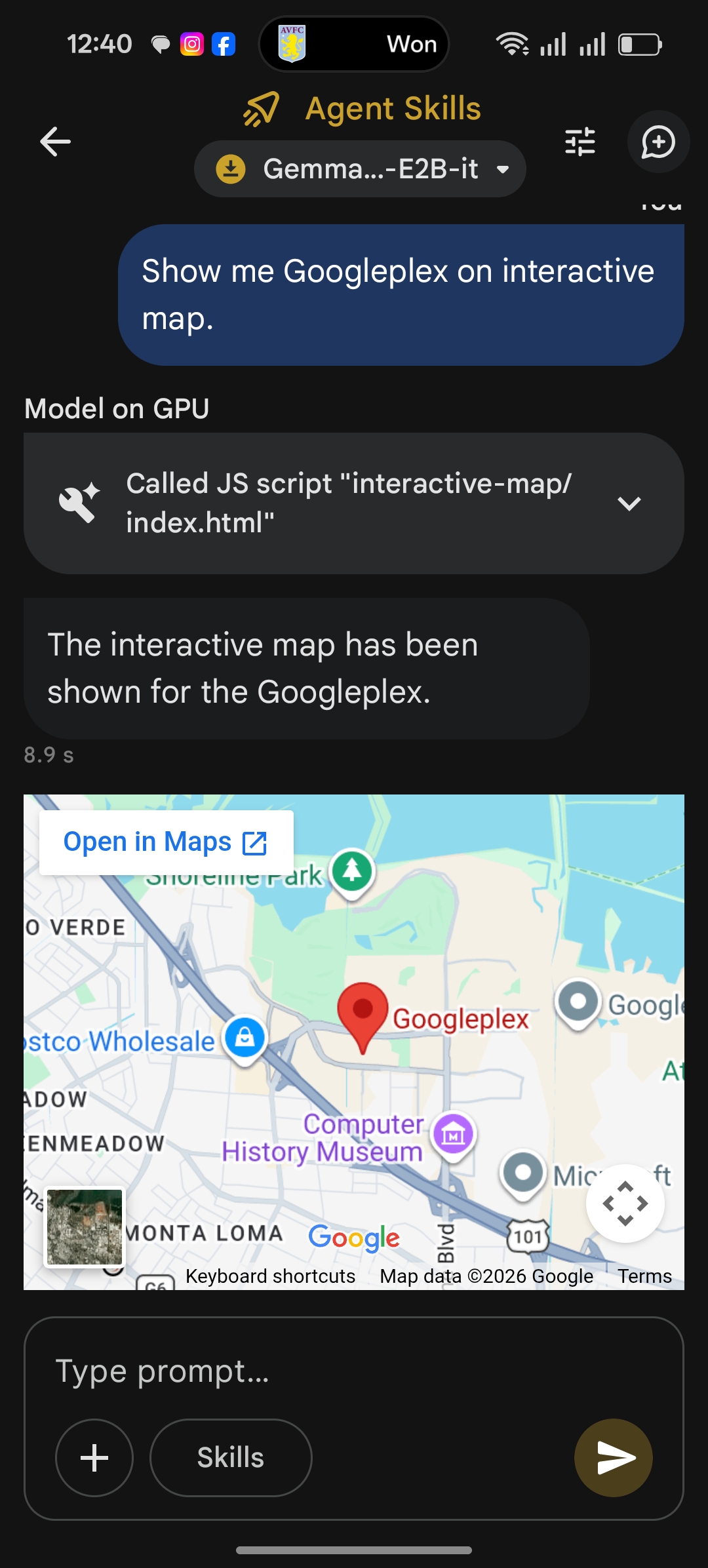
Interactive Maps — I tested an AI agent skill that generates interactive Google Maps outputs. The 2B model handled it in 8.9 seconds. For developers building location-aware applications, this is a significant capability to have running offline.
Custom Skills — you can import your own skills locally or load them from a URL. This is where the platform gets genuinely interesting for developers , it is an extensible AI runtime, not just a demo app.
Prompt Lab — a built-in workspace for text summarisation, tone rewriting, and code snippet generation.
The one limitation worth flagging: there is no option to upload images directly in the chat interface, which means testing Gemma's multimodal capabilities requires going through the Ask Image workflow rather than inline attachment. For a multimodal model this feels like an interface gap that will likely be addressed in future releases.
Hardware Reality: What 8GB Actually Means in 2026
Running these models is free. The OnePlus handled everything without crashing, but the constraints are real.
Memory pressure is constant. With 8GB RAM, the system is near its limit when a 4B model is active. Switching to a memory-heavy app while the model is generating will likely trigger Android's Low Memory Killer, terminating the AI process. If you are using the AI for something important, keep your attention on it. 8GB is the floor for running the 4B model. 12GB or 16GB is the practical target for comfortable daily use.
Thermal throttling is a real concern. The 3.5-minute chemistry problem made the phone noticeably warm. The GPU did not emergency-shutdown, but sustained use of the 4B model on complex reasoning tasks will eventually lead to thermal throttling which will slow token generation over time. For quick tasks the 2B model avoids this entirely.
The warning screen is honest. "Proceed Anyway" is the correct choice for developers who want to test the limits. It is also a reminder that we are early in this technology's maturity on mobile hardware.
The Kenya Context: Why This Matters
Two things make local AI more than a technical curiosity in Kenya specifically.
Data compliance. The ODPC has become increasingly active on cross-border data flows. For a startup handling mobile money transaction data, health records from a rural clinic, or any personally identifiable information, sending that data to a server in Virginia or Dublin for AI processing is no longer just a latency question, it is a compliance risk. A model running on the device that generated the data eliminates the transfer entirely.
Connectivity independence. Reliable high-speed internet is not universal in Kenya. An AI model that runs at 40 tokens per second with the phone in Airplane Mode works on a matatu, in a remote farming community in Nakuru, and in a hospital clinic far from Nairobi's fibre infrastructure. The intelligence is on the device. The connectivity requirement is zero.
For students, this is particularly significant. An offline tutor that can solve university-level problems (correctly, as the 4B demonstrated) lowers the barrier to access in ways that cloud-dependent AI cannot.
The Honest Summary
Use Gemma 4-2B for: content generation, drafting, chat interfaces, structured data, quick lookups, anything where speed matters more than precision. It is fast enough to feel instant, capable enough for most daily tasks, and thermally comfortable for extended use.
Use Gemma 4-4B for: anything involving truth. Maths, scientific reasoning, financial calculations, logic chains. It takes its time, it warms your phone, and it gets the answer right when the smaller model gives you a confident hallucination.
The 2B model is a poet that sometimes lies. The 4B model is a scientist that takes its time.
Both of them run on a phone you can buy in Nairobi for under Ksh 35,000. Neither of them needs the internet. That is the story of local AI in 2026, not that it is perfect, but that it is here, it is accessible, and it is already useful in ways that matter.
How to Try It Yourself
Search Google AI Edge Gallery on the Google Play Store and install it (11MB)
Open the app and select a model from the library
Choose Gemma 4 E2B for speed or E4B for reasoning
Tap the model, wait approximately one minute for it to load into RAM
Accept the RAM warning and proceed
Start prompting — no account, no API key, no internet required
The era of local AI has arrived in Kenya. It is warm, it is memory-hungry, and it is genuinely brilliant.
Comments